浏览量:5151 最近编辑于:2022-06-15 19:32:00
#数据爬取
##网页分析
打开链家北京二手房成交首页:`https://bj.lianjia.com/chengjiao`,如下图所示:
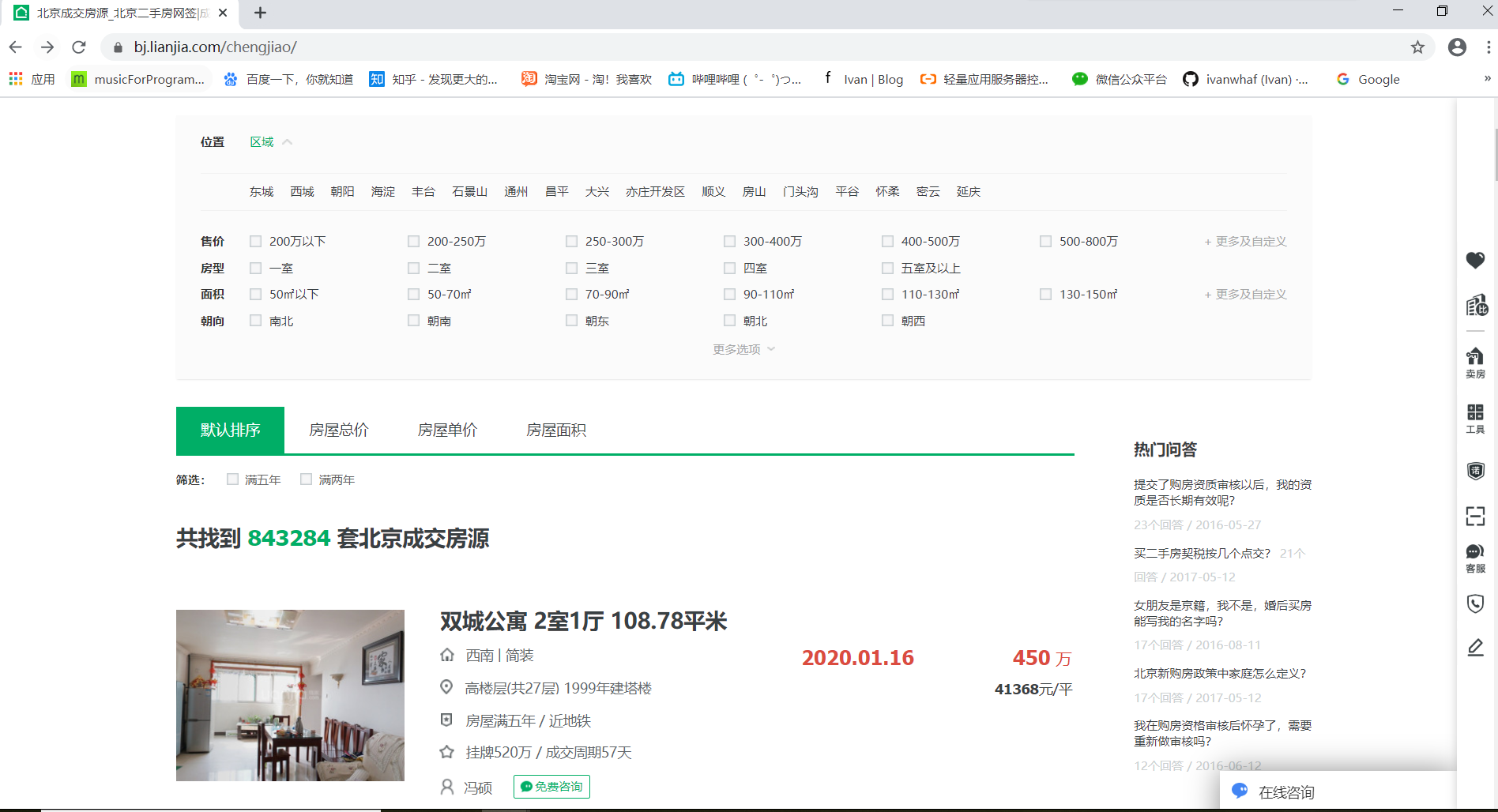
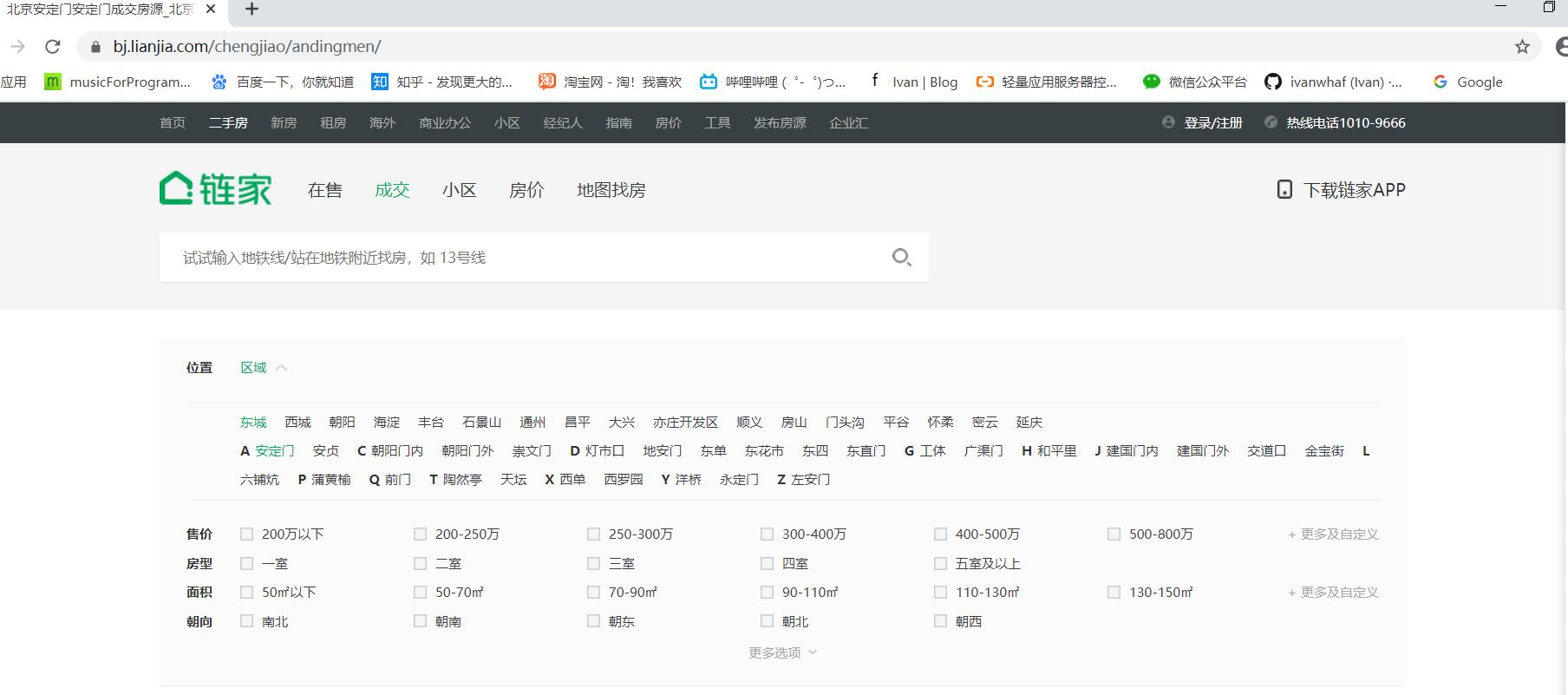
这里我们随便点击一个区,观察url变为`https://bj.lianjia.com/chengjiao/`加`区拼音`的格式,如下图所示,东城区的url为:`https://bj.lianjia.com/chengjiao/dongcheng`,再点击区下面的随便一个街道,url变为`https://bj.lianjia.com/chengjiao/`加`镇/街道拼音`的格式,如东城区安定门街道的url为`https://bj.lianjia.com/chengjiao/andingmen/`
按F12打开控制台,检视页面元素发现各个区的url存在于属性为“data-role=ershoufang”的div标签的a子标签中,如下图:
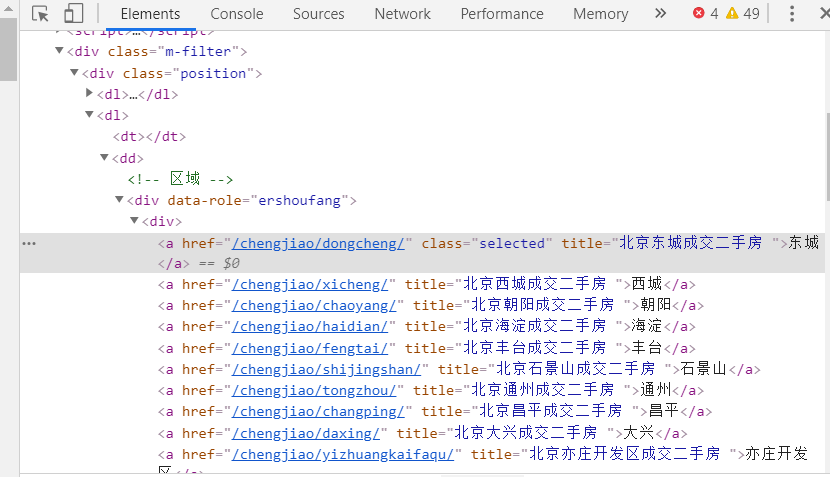
这时,我们的思路是获取所有区对应的二手房成交信息的url,通过遍历上述div将url存入内存中。再构造一个**区-镇-房字典rdic**,每个区作为字典的键,每个**{镇:[房]}**嵌套子字典作为值。需要注意的是,每个区最多有100页,每页30条记录,也就是每个区最多能显示3000条记录。因为大部分区的成交数都小于3000,所以基本不用担心记录显示不全的问题。下图为获取rdic字典函数:
```python
def get_areas():
rdic={}
r=requests.get(cj_url,headers=headers)
soup=bs(r.text,'html.parser')
tag_a=soup.find('div',attrs={'data-role':"ershoufang"}).find_all('a') # 区域div中的每一个a标签对应一个区
for a in tag_a:
district=a.text # 区名称
rdic[district]={}
dis_href=a.get("href") # 每个区对应的url后缀,例如:"/chengjiao/dongcheng/"
dis_url=main_url+dis_href # 每个区成交记录的url
r=requests.get(dis_url,headers=headers)
soup=bs(r.text,'html.parser')
tag_a2=soup.find('div',attrs={'data-role':"ershoufang"}).find_all('div')[1].find_all('a') # 镇/街道div中的每一个a标签对应一个镇/街道
for a2 in tag_a2:
town=a2.text # 镇/街道名称
town_href=a2.get("href") # 每个镇/街道对应的url后缀,例如:"/chengjiao/andingmen"
town_url=main_url+town_href
print(town_url)
rdic[district][town]=town_url
return rdic
```
接着我们打开房源详情界面:
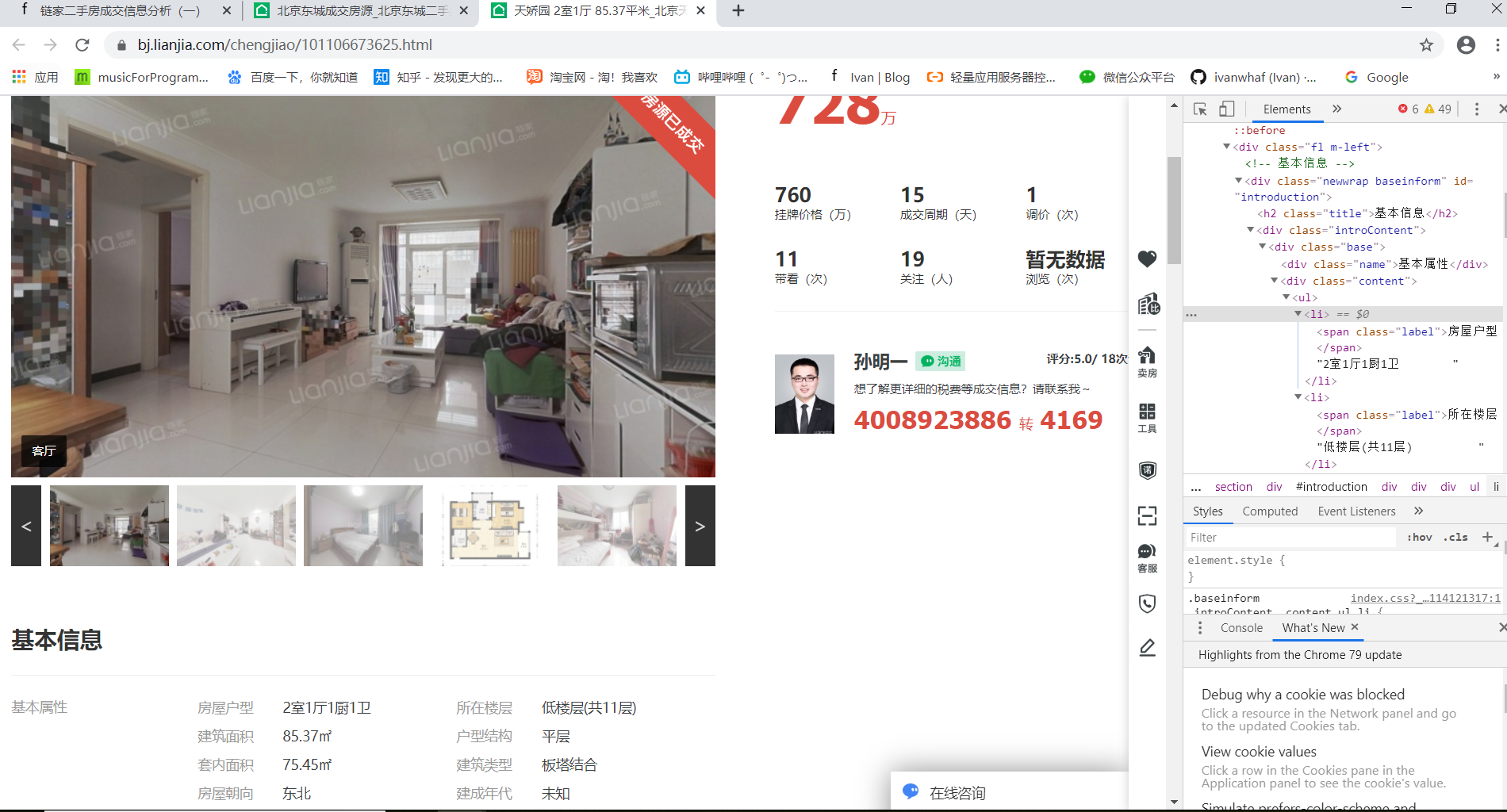
同样的,通过控制台获取到房源的详细信息,如:名称、成交价格、户型、楼层、面积、装修情况等。
##运行流程
至此,整个运行流程已经明确了,①获取所有区域url-->②遍历每个区域房源的url(100页),并添加至"区-镇-房"字典中-->③爬取每个房源详情界面获取详细记录-->④保存记录至excel
#数据保存
将爬取的数据先存至pandas的DataFram中,每爬完一个区保存一次excel,最后调用`data.to_excel(path+"lianjia.xlsx",columns=columns)`方法将全市总数据导出至总excel中。